Donglin Zeng

Professor
Department of Biostatistics
Gillings School of Global Public Health, CB#7420
University of North Carolina at Chapel Hill, 27599-7420
Education
B.S.(major in pure mathematics), Department of Mathematics, University of Science and Technology of China,
1993
M.S. (major in
partial differential equations), Department of Mathematics, University of Science and Technology of
China, 1995
Ph.D., Department of Statistics, University of Michigan, 2001
Teaching Activities
Course I. Semiparametric Models in Health Science, Fall 2002
Course II. Advanced Probability and Statistical Inference (I), Fall
2004
Course III. Advanced Probability and Statistical Inference (I), Fall
2005
Course IV. Advanced Probability and Statistical Inference (I), Fall
2006
Course V. Advanced Probability and Statistical Inference (I), Fall
2007
Workshop. Empirical Processes and Statistical Applications, Jul-Oct
2008
Course VI. Advanced Probability and Statistical Inference (I), Fall
2009
Course VII. Statistical Learning and
High-Dimensional Data, Spring 2011
Course VIII. Advanced Probability and Statistical Inference (I), Fall
2011
Course VIV. Advanced Survey Sampling Methods,
Spring
2013
Course X. Advanced Probability and Statistical Inference (I), Fall
2015
Course XI. Advanced Probability and Statistical
Inference (I), Fall
2016
Course XII. Statistical Learning and Personalized Medicine, Spring 2018
Course XIII. Advanced Probability and Statistical
Inference (I), Fall
2019
Research Interest
My current interest is method development on machine learning, personalized medicine, semiparametric
inference and high dimensional inference, with particular applications to EHR data, clinical trials, survival
data and genetics in biomedical studies. Other applied areas I involve
include medical diagnostics in breast imaging and AIDS.
Some
recent work can be found in my curriculum vitae.
Some
algorithms and codes related to
my research on semiparametric transformation models are also available.
Another page displays simulations for the
meta-analysis.
My personal research interest, probably future interest, also includes linear/nonlinear
functional analysis, which I respectfully view as the most pretty pearl in
abstract sciences.
Selected Publications
1. D. Zeng, Estimating Marginal Survival Function by Adjusting for
Dependent Censoring Using Many Covariates, Annals of Statistics, 2004.
2.
D. Zeng, Likelihood Approach for Marginal Proportional Hazards Regression
in the Presence of Dependent Censoring, Annals of Statistics, 2005.
3.
D. Zeng and J. Cai, Asymptotic Results for Maximum Likelihood Estimators
in Joint Analysis of Repeated Measurements and Survival Time, Annals of Statistics, 2005.
4.
D. Zeng, D.Y. Lin and G. Yin, Maximum Likelihood Estimation in the
Proportional Odds Model with Random Effects, Journal of the American Statistical Association, 2005.
5.
D. Zeng, G. Yin and J. Ibrahim, Inference for a Class of Transformed Hazards Model,
Journal of the American Statistical Association, 2005.
6.
D.Y. Lin and D. Zeng, Likelihood-Based
Inference on Haplotype Effects in Genetic Association (with
discussions),
Journal of the American Statistical Association, 2006.
7.
D. Zeng, G. Yin and J. Ibrahim, Semiparametric Transformation Models for Survival Data
with a Cure Fraction,
Journal of the American Statistical Association, 2006.
8.
D. Zeng and D.Y. Lin, Maximum likelihood
estimation in semiparametric
transformation models for counting processes
, Biometrika, 2006 and its technical report.
9.
D. Zeng and D.Y. Lin, Semiparametric Transformation
Models With Random
Effects for Recurrent Events,
Journal of the American Statistical Association, 2007.
10.
D. Zeng and D.Y. Lin,
Maximum Likelihood Estimation
in Semiparametric Models with Censored Data (with discussion).,
Journal of the Royal Statistical Society B, 2007.
11.
D. Zeng and D.Y. Lin,
Efficient Estimation in the Accelerated Failure
Time Model,
Journal of the American Statistical Association, 2007.
12.
Q. Chen, D. Zeng and J. Ibrahim, Sieve Maximum Likelihood
Estimation for Regression Models with
Covariates Missing at Random, Journal of the American Statistical
Assoication, 2007.
13.
B. Johnson, D. Y. Lin, and D. Zeng, Penalized Estimating
Functions and Variable Selection in Semiparametric Regression
Models, Journal of the American Statistical
Assoication, 2008.
14.
G. Yin, H. Li, and D. Zeng, Partially Linear
Additive Hazards Regression with Varying Coefficients, Journal of the
American Statistical
Association, 2008.
15. D. Zeng, Q. Chen and J. Ibrahim, Gamma-Frailty Transformation Models for Multivariate
Survival Times, Biometrika, 2009.
16. D. Zeng and D.Y. Lin, A Generalized Asymptotic
Theory for Maximum Likelihood Estimation in Semiparametric Regression Models
with Censored Data, Statistica Sinica, 2009.
17. D. Zeng and J. Cai Semiparametric Additive Rate Model for
Recurrent Events with Informative Terminal Event, Biometrika,
2010.
18. D.Y. Lin and D. Zeng On The Relative Efficiency of Using Summary
Statistics versus Individual Level Data in Meta-Analysis
, Biometrika, 2010.
19. Y. Wang, T. Chen and D. ZengSupport Vector Hazards Machine: A Counting Process Framework for Learning Risk Scores for Censored Outcomes, Journal of Machine Learning Research, 2016.
20. Y. Wang, P. Wu, Y. Liu, C., C. Weng and D. Zeng Learning Optimal Individualized Treatment Rules form Electronic Health Record Data, IEEE International Conference on Healthcare Informatics: ICHI 2016 proceedings, 2016.
Selected Personal Views
-
Nowadays, everyone would like to call him/herself a data scientist. But nobody knows what is exactly data science?
I create the following contrasts that hopefully can help a bit in thinking.
Data Engineering vs Data Science
Precision Science vs Population Science
Exploratory Science vs Mechanism Data Science
Empirical Learning vs Generalizable Learning
Interpretable Machine Learning vs Justifiable Machine Learning
-
Data analytics driven by mathematics or by computation?
This conflict has become even more obvious with advance of computing technology and urgence of anlayzing big data. Traditionally, mathematicians (more precisely, mathematical statisticians) tend to come up with flexible and robust models for analyzing data such as nonparametric or semiparametric models. They provide smart ways (well, need a lot of theory) to produce results in optimal ways. However, there is a growing trend in statistical fields (publications) that people like to use complex and parametric models (generative models, hiearchical neural networks) for data analysis, without worrying much about model misspecification or theory. This is certainly useful with need to analyze big data and takes advantage of "free" computing power. Optimality of the results is less concern as compared to computability. Hence, an interesting question is how to balance data analytics driven by math and by computation. My view is that the latter is useful for model discovery and exploration while the former is useful for inference and decision making, kind of aligning with two levels in my data science pyramid. Another prediction is that similar to evoluation of math and phycics which is known to take sin and cos function shapes, peak time of mathematical data sciene is down time of computational data science and vice versa. We will see.
- I often think about where we, as statisticians, are in the era of Big Data. As more and more data emerge these days, researchers from all different fields including us are certainly excited to seek more data evidence to improve and test their own models and methods. However, Big Data does not necessarily mean Big Evidence and it is usually not; moreover, Cheap Data are often Poor Data. Therefore, it is important for us to ensure scientific quality of data, representativeness of data, and generalizability of findings, which is exactly the whole driving force of Statistics in terms of handling random errors, sampling and probabilistic inference. By saying that, I think that we should maintain this important value and unique identity of our researches, instead of being torn away by case-specific methods purely driven by individual data and specific tasks. Evidence-based decision making should always be combined with theory-guided decision making! At the same time, we need to learn from different disciplines, especially computer science, to effectively handle data storage, processing and analysis, combine global analytic objectives and local analytic objectives, and eventually efficiently translate our work into practice.
I create this pyramid for data science (I am sure that workforce in data science has the same pyramid shape--hope salary too -:)).
Data Science Pyramid 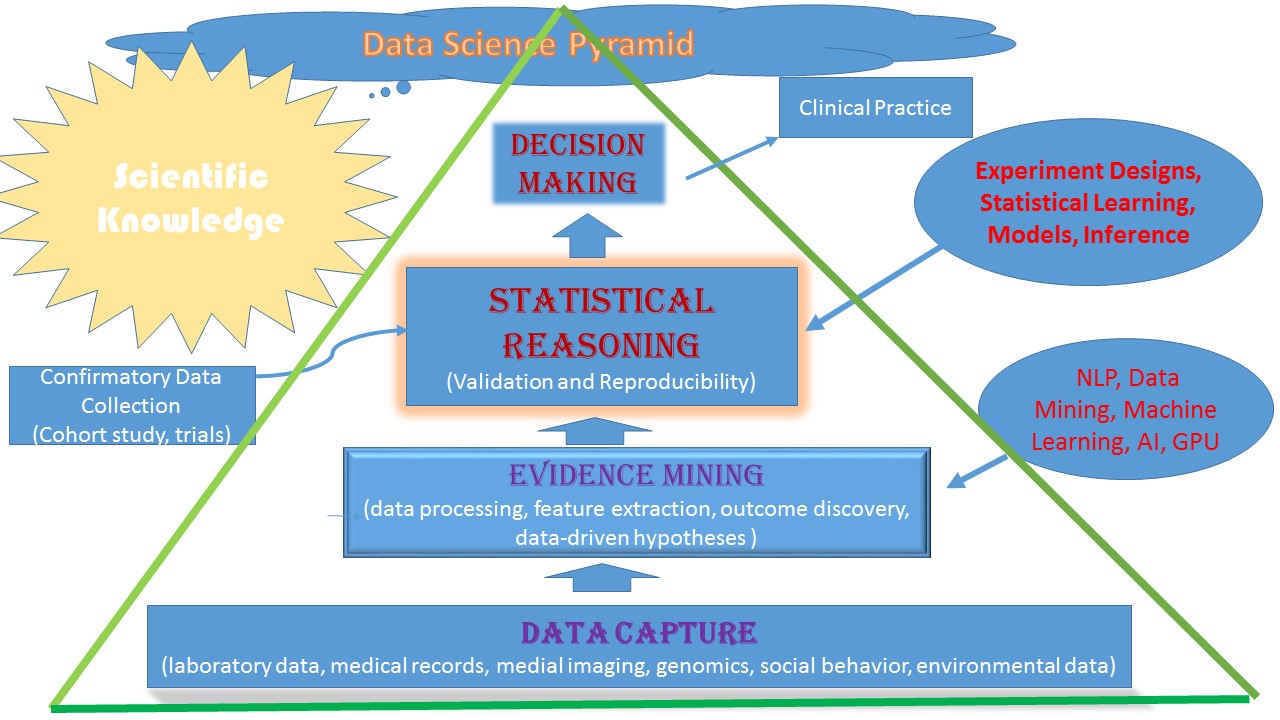
!!! As statisticians, we should be proud where we are in the pyramid --- it is us who can directly interact with and influence decision makers and clinical users--HOORAY!!!
- High-dimensional variable selection has been the most eye-catching topic in journal publications. However, only till recently do we start to look into post-estimation inference concerning non-regularity of inference. I think that this should be the most important goal from now on, given plenty of regularization methods in this area--maybe every single statistical paper on high-dimensional estimation should have a big component on obtaining correct inference (not point-wise but should be locally regular). For prediction purpose, certain oracle selection may be a good choice; however, concerning inference, non-oracle selection should be used, which exactly reflects the fact of Uncertainty Principle (trade-off between precision and stability). I notice there have been interesting development from Zhang, van der Geer and Belloni's groups using orthogonalization ideas. However, one of my general thoughts is whether we can cast this problem into semiparametric inference problems (for semiparametric models, nuisance parameters are usually infinite-dimensional so certainly high-dimensional), treating the vector of coefficients in some l_2 space (infinite dimensional vector) so the sparsity being some compact set of this space. There have been well-known results in semiparametric framework to construct efficient estimation for parameter of interest and obtain valid inference even if the nuisance parameter is estimated far slower than parametric-rate. I am sure that those results can be useful. Furthermore, we can not only obtain correct inference for one single coefficient but also some "smooth" functional of the whole vector of coefficients (this is known in semiparametric inference). This may be a good direction towards to high-dimensional inference with local regularity, and certainly, it will revive interest of learning semiparametric inference from our students.
-
I wrote a short blog regarding causal inference and I know the same concept has been discussed by other before. I am not trying to change any existing causality framework but just think it may be useful to accelerate drug development, given the difficulty of conducting a perfect randomization study but with the increasing knowledge of patient's information in the Big Data era.
Some stories to share
Story 1: A while ago, someone told someone who told me this--Any science that tries to name itself "Science" is actually not real science (he reminded me about Mathematics, Physics, Chemistry, Biology)--I don't think they meant to be offensive but it is worth our thinking.
Story 2: This is my own story. The other day, I went to a museum with my data science friend and saw this display:

Our immediate response was "Wow! Artificial Intelligence Data Science!" Akwardly enough, it turned out to be a display for AIDS (Acquired Immune Deficiency Syndrome). Later after I came back, I found it very intriguing to ask myself the following question:
Is A-I-D-S (Artificial Intelligence Data Science) really an "aid-Science" (aid-S) by making human more intelligent, life more efficient and society more fair, or,
can it become Acquired Immune Deficiency Syndrome (AIDS) for science by dysfunctioning human evolution and impairing value systems?
Another thing worth deep thought and learning, right?